
Teaching Language Models to Reason with Just 13 Parameters
How Meta researchers achieved 91% accuracy on math problems by training just 26 bytes and what it reveals about the fundamental difference between supervised learning and reinforcement learning.

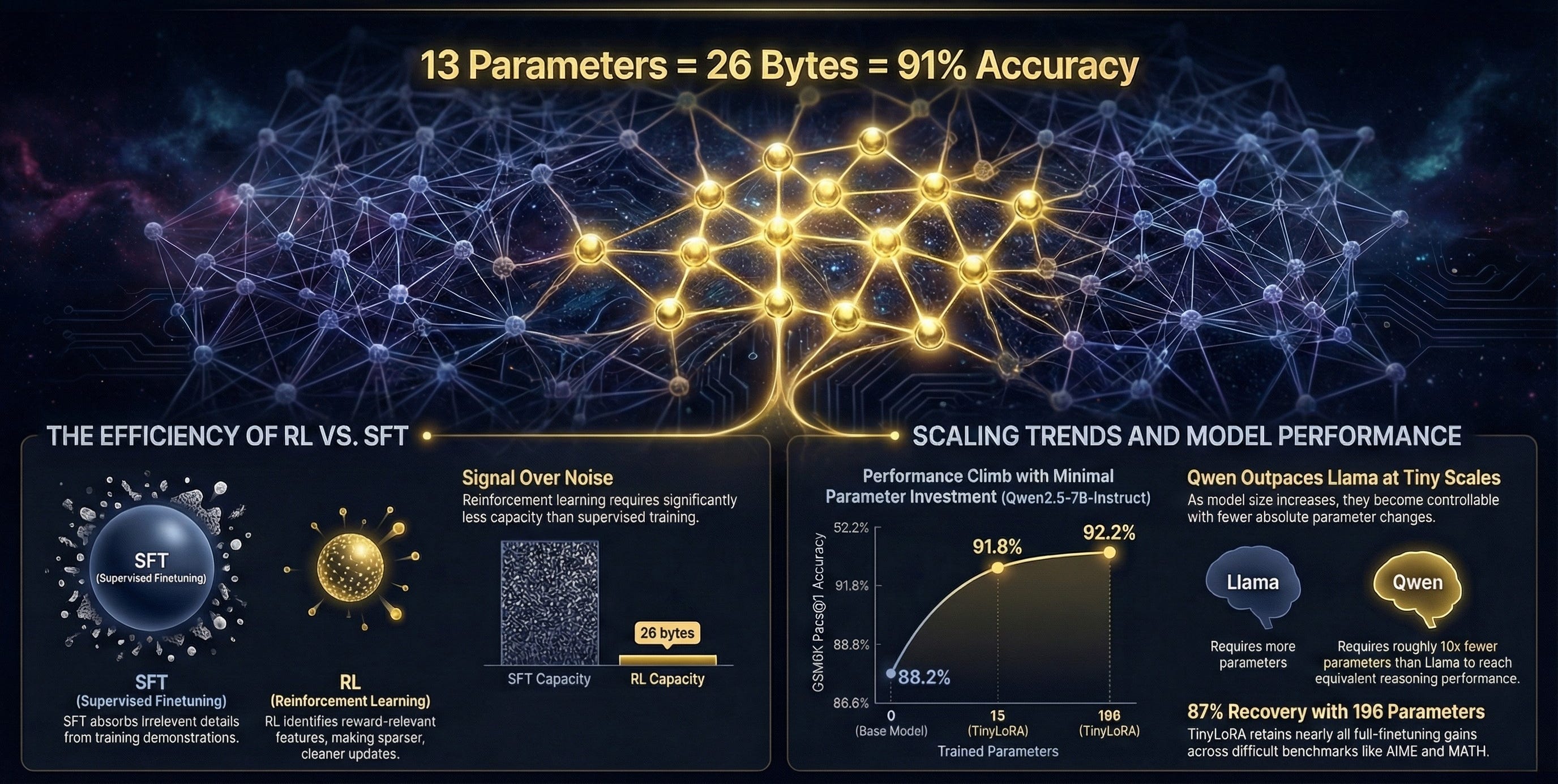
Researchers at Meta FAIR (Fundamental AI Research) have achieved something that sounds impossible: they trained an 8-billion parameter language model to solve math problems at 91% accuracy while updating only 13 parameters. That’s 26 bytes total small enough to fit in a tweet with room to spare.
The paper Learning to Reason in 13 Parameters by Morris et al. introduces TinyLoRA, a method that pushes parameter-efficient fine-tuning to its theoretical limits. More importantly, it reveals a fundamental difference in how supervised learning and reinforcement learning work when teaching models to reason.
The Core Problem
When you want to improve a language model’s reasoning ability; say, teaching it to solve math word problems; the standard approach is fine-tuning. Full fine-tuning updates billions of parameters, which is expensive in memory, computation, and distributed training overhead. Low-Rank Adaptation (LoRA) reduced this to millions of parameters, a huge improvement. But the researchers asked a more fundamental question: how few parameters can we actually get away with?
The answer turns out to depend critically on how you train. With supervised fine-tuning, you need substantial capacity; hundreds of thousands to millions of parameters to absorb the training signal. With reinforcement learning, you can achieve comparable results with just hundreds or even tens of parameters.
If reinforcement learning can match supervised learning performance with three orders of magnitude fewer parameters, it suggests the two approaches are solving fundamentally different problems.
Why Reinforcement Learning Changes
The key insight is about information density. In supervised fine-tuning, the model learns by imitating complete solution demonstrations. It sees here’s a problem, here’s how to solve it and tries to reproduce that pattern. The training signal is dense but noisy; the model can’t easily distinguish which parts of the demonstration are essential for correctness versus stylistic choices or irrelevant details. Without a mechanism to separate signal from noise, supervised learning must treat all tokens as equally informative, forcing it to store both useful structure and irrelevant particulars.
Reinforcement learning presents a cleaner signal. The model generates multiple solution attempts and receives binary feedback: correct or incorrect. The useful information lies entirely in the reward, which amounts to just a few bits per training example. But this sparse signal is cleanly separated from noise. Features that correlate with correctness accumulate through repeated sampling, while uncorrelated variation cancels out. The model can focus exclusively on what matters for task performance.
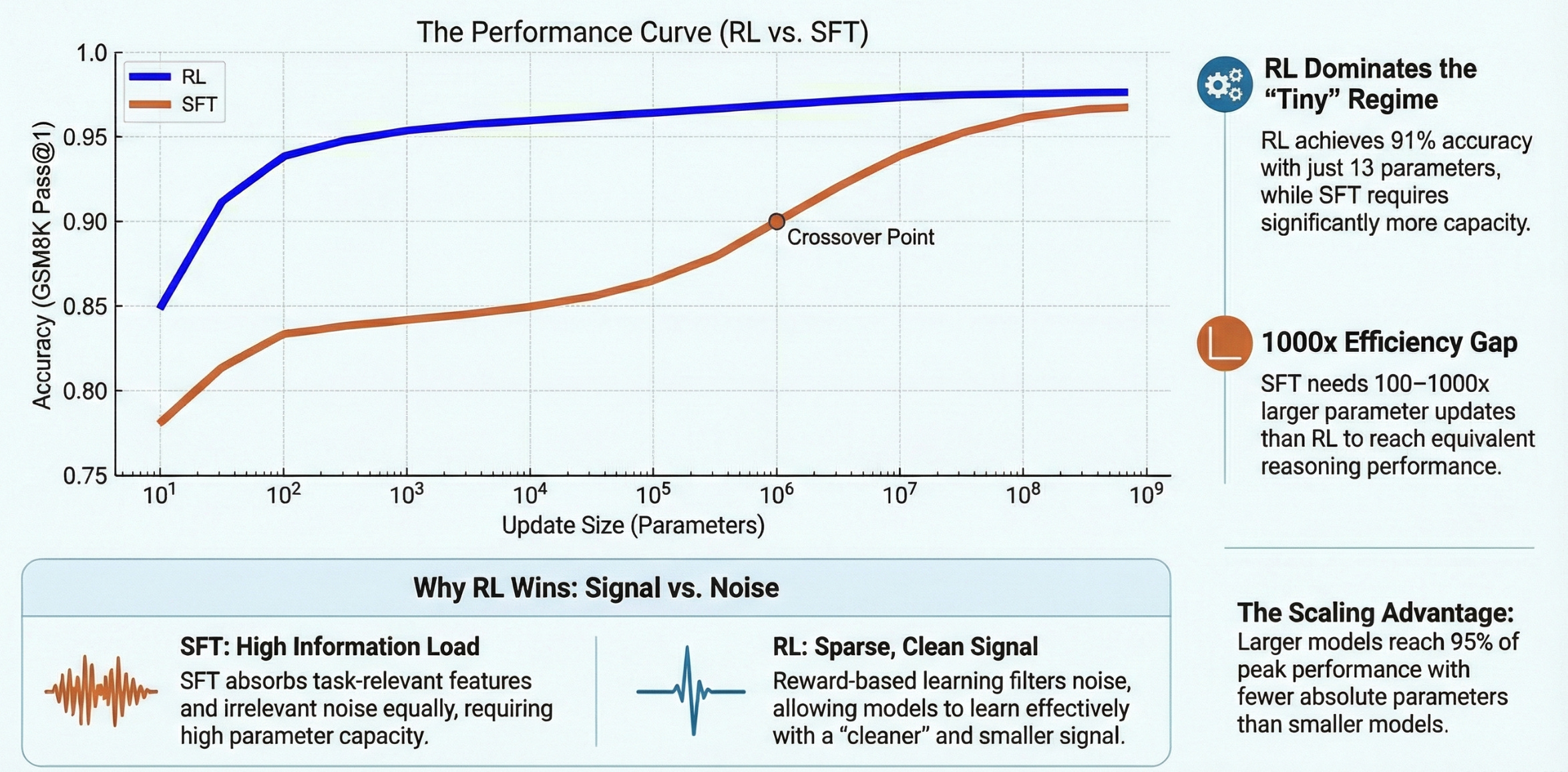
This explains why RL thrives in the ultra-low-parameter regime while supervised learning struggles. RL doesn’t need to memorize solution patterns; it just needs to learn which directions in parameter space increase the probability of reward. That’s a fundamentally simpler learning problem.
How TinyLoRA Works
Standard LoRA adapts a frozen weight matrix by adding a low-rank update, typically requiring thousands to millions of parameters. LoRA-XS improved on this by learning to recombine the dominant singular directions of the original weight matrix, reducing parameter count to the square of the rank.
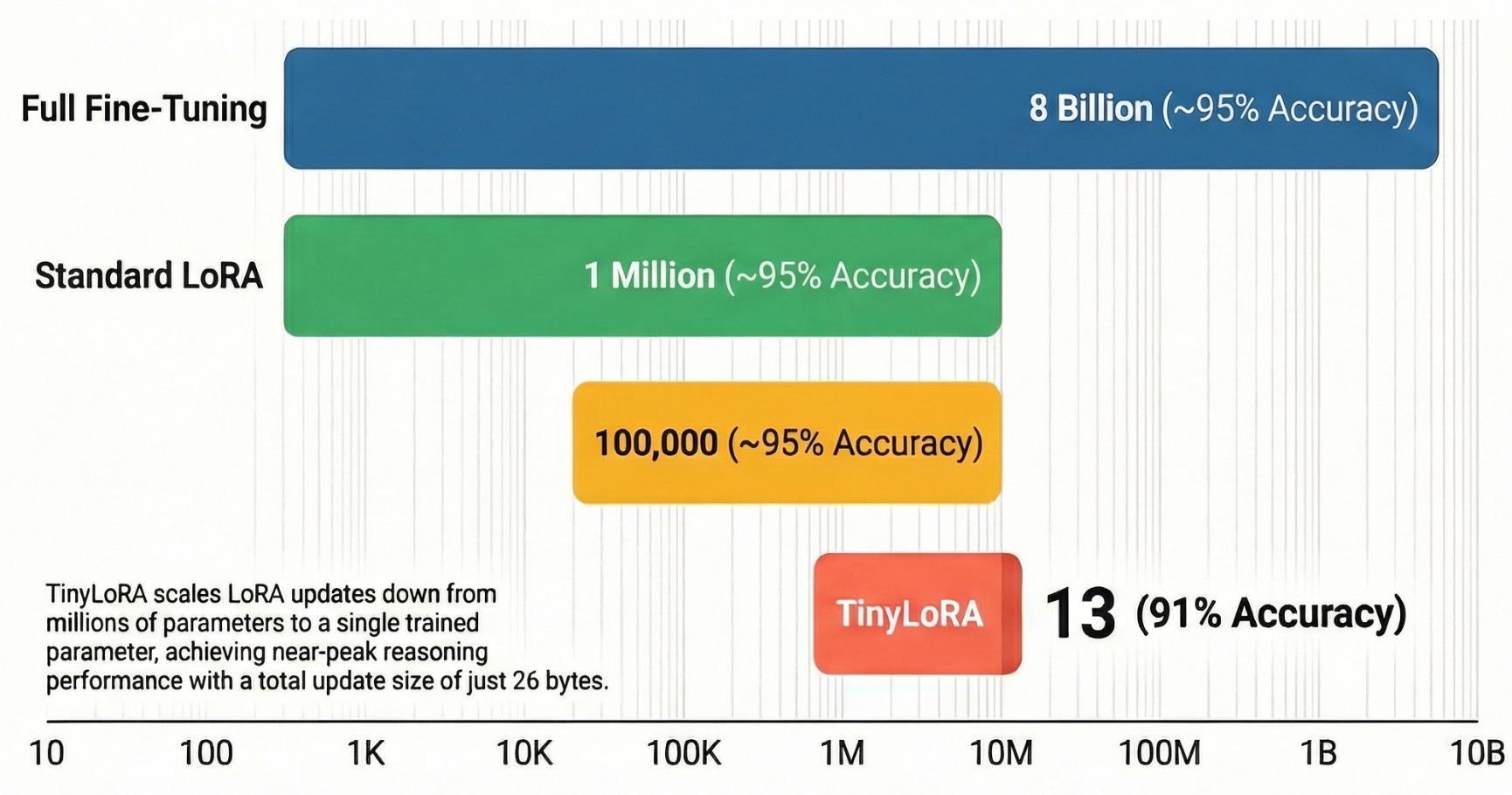
TinyLoRA goes further. Instead of training a full low-rank matrix, it trains a tiny vector that gets projected through a fixed random tensor to produce the weight update. With aggressive weight sharing across all transformer modules; attention and feedforward layers alike - the total trainable parameters can drop to single digits.
The method achieves 91% accuracy on GSM8K math problems with Qwen2.5-7B-Instruct using just 13 parameters. To put this in perspective, the baseline model starts at 76% accuracy. Training 13 parameters delivers a 15 percentage point improvement within 5% of what full fine-tuning achieves.
What the Experiments Show
The researchers evaluated TinyLoRA across multiple model families (Qwen and LLaMA), model sizes (0.5B to 8B parameters), and benchmarks (GSM8K, MATH, AIME, AMC, and others). Several patterns emerged consistently.

First, the gap between RL and supervised fine-tuning is dramatic at low parameter counts. With RL and 10,000 parameters, Qwen2.5-7B-Instruct reaches 95% on GSM8K. With supervised learning and the same parameter budget, it barely scratches 84%. The supervised learning curve only catches up to RL when you increase capacity to hundreds of thousands of parameters.
Second, larger base models require fewer trained parameters to reach the same fraction of maximum performance. A 7B model can hit 95% of its ceiling with hundreds of parameters, while a 3B model needs thousands. This suggests that trillion-parameter models may be controllable with remarkably small adapters.
Third, the Qwen model family proves roughly 10 times more parameter-efficient than LLaMA at equivalent scales. With just 100 parameters trained, Qwen reaches 74% accuracy while LLaMA manages only 60%. The reasons for this gap remain unclear—it could reflect architectural differences, pretraining data, or exposure to similar problems during pretraining.
Fourth, in the extremely constrained regime (under 1 kilobyte total), storing parameters in 32-bit floating point outperforms 16-bit formats even after accounting for the doubled storage cost. This suggests that numerical precision matters when you have almost no capacity to work with.
Limitations and Open Questions
The results are striking but come with important caveats. All experiments focus on mathematical reasoning tasks—word problems, competition mathematics, and similar domains. Whether these findings generalize to other reasoning domains like scientific problem-solving, code generation, or creative writing remains an open question.
The paper also doesn’t deeply investigate what is actually being learned. One hypothesis is that the base model already contains the necessary knowledge, and the tiny adapter merely adjusts the output style; perhaps learning to generate longer, more structured responses that improve accuracy. Testing this would require careful analysis of what changes in the model’s internal representations.
The comparison between RL and supervised learning also raises questions about on-policy versus off-policy dynamics. The supervised experiments train on fixed expert demonstrations (off-policy), while RL continuously samples from the current policy (on-policy). The authors acknowledge this confound but don’t fully disentangle its effects.
Finally, the work relies on verifiable rewards; problems with objectively correct answers. Extending these methods to domains without clear correctness signals would require different techniques.
Thanks for reading The Neural Blueprint! If you found this useful, consider sharing it with someone who’s curious about Language Models to Reason with Just 13 Parameters! Share The Neural Blueprint
Why This Matters
The immediate practical benefit is efficiency. Smaller adapters reduce memory footprint, speed up distributed training, and enable serving more personalized models concurrently. A 1000-fold reduction in adapter size means 1000 times more users can have custom models loaded simultaneously.
But the deeper implication concerns how we think about post-training. If reinforcement learning can match supervised learning performance with three orders of magnitude fewer parameters, it suggests the two approaches are solving fundamentally different problems. Supervised learning builds broad capabilities by absorbing diverse training patterns. Reinforcement learning amplifies specific capabilities already latent in the base model.
This aligns with recent findings that RL generalizes better out-of-distribution, forgets less, and primarily reshapes how existing knowledge gets expressed rather than injecting new knowledge. The extreme parameter efficiency demonstrated here provides additional evidence for this view.
For practitioners, the lesson is clear: when your task has verifiable correctness and your base model is large and capable, reinforcement learning with tiny adapters may be surprisingly effective. For researchers, it opens questions about the intrinsic dimensionality of different learning objectives and whether we can push these limits even further.
📄 Paper Link: https://arxiv.org/abs/2602.04118
👥 Authors: Morris et al.
PS: All infographics were created using Google NotebookLM, with content drawn from the original research paper to ensure accurate representation and enhanced readability.
Subscribe to The Neural Blueprint
By Vijendra
Deconstructing the architecture of modern AI systems