

Scalable Systems Guide: 7 Layers Every Dev Should Know
Learn how to build scalable systems using a 7-layer model. Real-world tips, tools, and Netflix examples. Read now to audit your architecture.

Hey there, fellow builders,
Let’s talk about scale. Not the kind in your bathroom, but the kind that determines whether your product explodes in a good way... or crashes when traffic spikes. Because if you’ve ever been paged at 3 a.m. thanks to a system meltdown, you already know: scalability isn’t optional. It’s survival.
We’re going to unpack what real scalability looks like, layer by layer, without fluff or buzzwords. Just the hard-earned stuff your future self will thank you for. Think Netflix-level system thinking, not MVP duct tape. Netflix didn’t go from DVD mailers to streaming billions of hours of video by duct-taping EC2 instances. They redesigned their stack, rewrote their culture, and rethought how every layer of their system worked. That’s the level of change we’re talking about.
In this guide:
You'll get a brutally honest breakdown of 7 system layers that actually matter.
Real-world stories (hello Netflix) to see how big players do it.
Tools, strategies, and patterns to start applying right now.
Skip ahead if you're hunting for something specific:
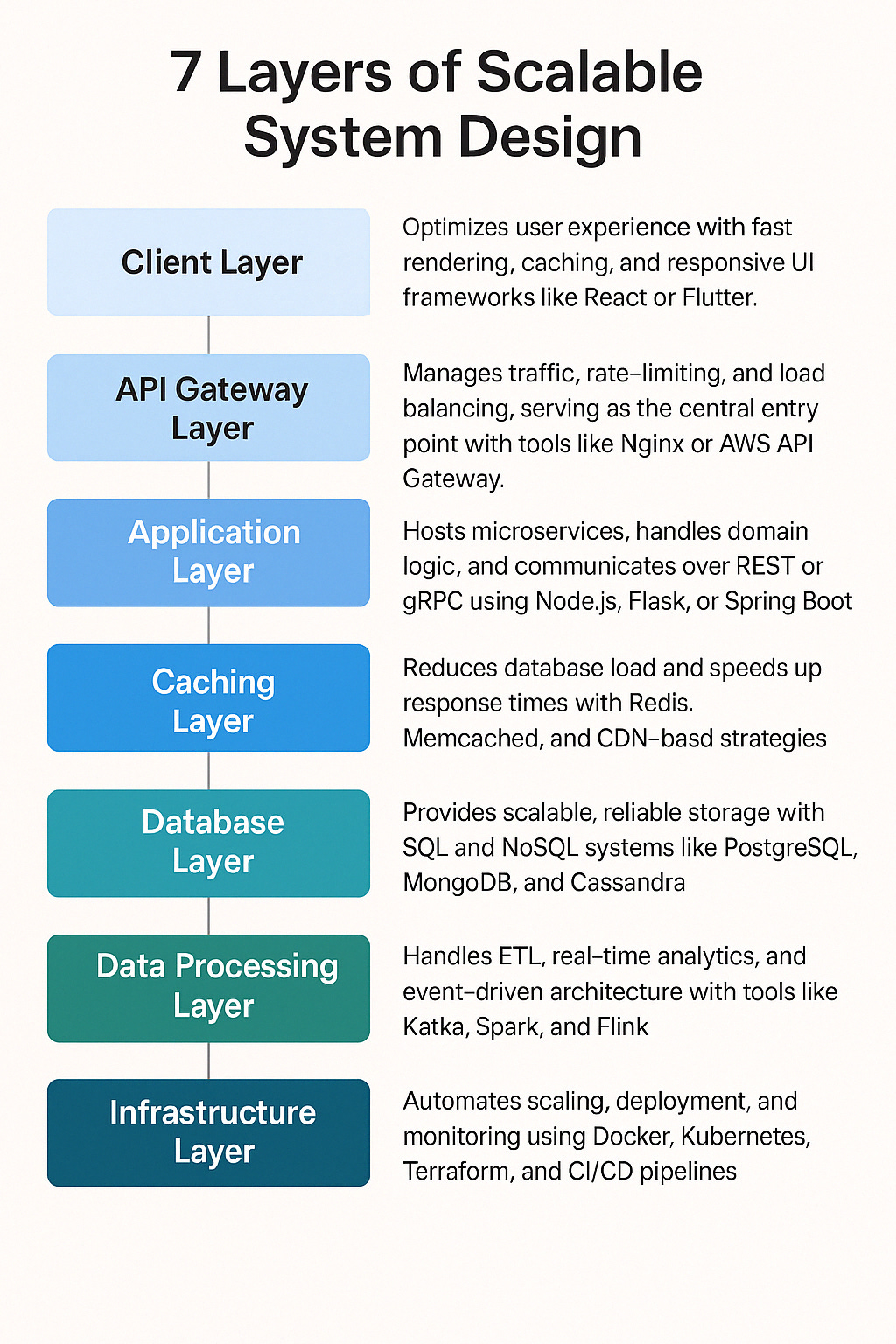
Layer 1: Client
Layer 2: API Gateway
Layer 3: Application
Layer 4: Caching
Layer 5: Database
Layer 6: Data Processing
Layer 7: Infrastructure
Here’s the thing, tech isn’t slowing down. Users expect apps to respond in milliseconds, scale instantly, and never go down. Even a hiccup during a Black Friday sale or livestream can turn users into ex-users.
And it’s not just hyperscalers. Even startups are expected to play like the big leagues. The days of “we’ll scale later” are done. Your architecture has to be designed for growth from day one.
The Core Challenges
Most systems fall apart for the same reasons:
Tight coupling: Everything depends on everything.
Single points of failure: One bug tanks the whole thing.
Short-sighted architecture: Built for 10 users, breaks at 100.
Over-reliance on databases: As if your DB can magically handle everything.
And worse? Teams don’t realize these are problems until the phone starts buzzing.
If you see someone struggling with scaling their app please do share this article
The Solution
Here’s the fix: a layered, composable system architecture. Think of your stack like a lasagna - each layer doing one job, built to scale independently. This guide walks through all seven layers:
Client – where users live
API Gateway – the gatekeeper
Application Logic – brains of the operation
Caching – memory with a purpose
Database – where the truth lives
Data Processing – where insights happen
Infrastructure – your rock-solid foundation
Let’s tear it down and rebuild it, one smart piece at a time.
How It Works
We’re going to walk through seven critical layers that make or break scalable systems. Think of this like tuning a Formula 1 car: if any part’s lagging, you lose.
1. Client Layer - Where Latency Feels Like Lag
This is where everything starts. Fast, efficient clients = happy users. No one cares how great your backend is if the UI lags.
Your job here:
Code splitting: Stop sending 1MB JS bundles. Use dynamic imports, lazy loading.
Skeleton screens > spinners: Give users the illusion of speed.
Service workers: For offline functionality and caching.
Caching strategies: Cache-first, stale-while-revalidate, whatever suits your flow.
Essential Technologies:
React, Vue.js, or Angular for web applications
Lighthouse for perf audits, Vite (blazing fast bundling), Tailwind (for consistency)
Flutter or React Native for cross-platform mobile development
Service Workers for offline functionality
WebSockets for real-time updates
📘 Must-read: High Performance Browser Networking by Ilya Grigorik
2. API Gateway Layer - Your Traffic Cop
This is the traffic cop. Every request passes through here. Do it right, and you get security, observability, and sanity. Screw it up, and you’re toast.
Patterns to follow:
Rate limit (yes, even your internal apps)
Authentication & authz
Route traffic based on version, region, language, etc.
Handle cross-cutting concerns (logging, request transformation, retries)
Best Practices:
Design consistent error handling across all endpoints
Implement circuit breakers to prevent cascading failures
Version your APIs to support graceful evolution
Use API keys and rate limiting to protect backend resources
Tools of choice: Kong, NGINX, AWS API Gateway, GraphQL
Watch Out For: Versioning hell. Start simple (v1, v2). But eventually you’ll need feature flags, A/B routing, and staged rollouts.
📘 Read: Building Microservices by Sam Newman
3. Application Layer - Where Logic Lives or Dies
This is your logic engine. Your business logic, rules, workflows, and it has to be modular. Most teams get here too fast, before fixing the edge layers.
Design Principles to Live By:
Stateless is king. You wanna scale? Kill session state.
Idempotency: Retry-friendly design. You’ll need this.
Bulkheads & Circuit Breakers: Prevent one bad service from nuking everything.
Domain-Driven Design: Avoid God classes and spaghetti modules.
Architectures That Work:
Microservices: Obvious.
Event-driven: Especially with Kafka or NATS.
Clean Architecture: Ports and adapters, baby.
Technology Options:
Node.js (lightweight), Spring Boot (enterprisey), Go (for tight systems) for service development
gRPC or REST for service communication
Docker for containerization
Kubernetes for orchestration
📘 Read: Clean Architecture: A Craftsman's Guide to Software Structure and Design by Robert C. Martin
4. Caching Layer - Your Secret Weapon
Speed without waste. Cache aggressively and smartly. It’s your system’s Red Bull.
Layers to think about:
Browser Cache-Control headers, ETags, localStorage (headers matter!)
Edge/CDN cache (Cloudflare, Akamai, Fastly)
Redis/Memcached (data cache)
App-level cache (pages, views)
Implementation Patterns:
Cache-aside (lazy loading) for on-demand caching
Write-through for data consistency
Time-to-live (TTL) strategies for cache invalidation
Cache warming for predictable performance
📘 Read: Database Internals: A Deep Dive into How Distributed Data Systems Work by Alex Petrov
5. Database Layer - Not Just Pick Postgres
Your source of truth. This is where things get real. Choosing a DB isn’t the endgame. It’s the starting point. The real challenge? Evolving schema, replication, migrations, failover, and query load.
Database Types and When to Use:
Relational (Postgres, MySQL): Normalized, strong consistency
NoSQL (Mongo, Dynamo): Flexible schemas, wide writes
Time-series (InfluxDB, Prometheus): Metrics, events
Graph (Neo4j): Relationships matter
Columnar (Cassandra): Massive scale, write-heavy
Scale Approaches:
Sharding (split by user/region/type)
Read replicas (for heavy reads)
Multi-region (with latency tradeoffs)
CQRS (separate read/write models)
Optimization Techniques:
Proper indexing strategies
Query optimization and execution plans
Connection pooling and resource management
Denormalisation for read performance
Netflix migrated from Oracle to Cassandra. Why? Oracle didn’t scale horizontally. Cassandra gave them write throughput and regional replication. But it wasn’t easy—they had to rewrite how they thought about data. They shard their databases by region and traffic type, using Cassandra heavily for availability and resilience.
📘 Read: Designing Data-Intensive Applications by Martin Kleppmann
6. Data Processing Layer: From Logs to Gold
Your pipeline for insights. Whether it’s real-time alerts or massive analytics jobs, this layer does the heavy lifting.
Architecture Patterns:
Batch Processing: For large volumes of historical data
Stream Processing: For real-time data analysis
Lambda Architecture: Combining batch and streaming approaches
Event Sourcing: Capturing all changes as a sequence of events
Technology Stack:
Apache Kafka or RabbitMQ for messaging
Apache Spark, Flink, or Storm for processing
Elasticsearch or Solr for text search and analytics
Hadoop ecosystem for big data workloads
Implementation Considerations:
Idempotent processing for reliability
Exactly-once vs. at-least-once semantics
Parallel processing strategies
Data partitioning for throughput
📘 Read: Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing by Tyler Akidau, Slava Chernyak, and Reuven Lax
7. Infrastructure Layer - The Real MVP
The base layer. Mess this up, and the whole thing comes down. Nail it, and you’ve got superpowers.
Essentials:
Containerization (Docker): Stop "works on my machine" lies
Orchestration (Kubernetes): Not perfect, but standard
IaC (Terraform, Pulumi): Infra versioned like code
Observability: Logs, metrics, traces
Best tools:
Docker for containerization
Kubernetes for container orchestration
Terraform or CloudFormation for infrastructure definition
Prometheus, Grafana, and ELK stack for monitoring
Ops Wisdom:
Implement auto-scaling based on demand metrics
Design for infrastructure immutability
Adopt blue-green or canary deployment strategies
Create comprehensive alerting with meaningful thresholds
📘 Read: Site Reliability Engineering: How Google Runs Production Systems edited by Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy
Deep Dive Example: Netflix
Netflix didn’t just scale. They redefined how systems scale. Layer wise few highlights:
Netflix engineers sweat over image loading speed. They track time-to-first-frame like it’s sacred. Why? Because if the client doesn’t deliver, everything downstream is wasted effort.
Netflix used BFFs (Backend-for-Frontends) for each client to avoid complexity at the edge. Smart move.
Netflix went hard on microservices early. They built hundreds. It gave them speed and scale, but came at the cost of observability. Hence, Simian Army and Chaos Monkey.
Netflix? Oh, they cache everything. CDNs serve video chunks, metadata gets cached aggressively in memcache, and even UI configurations are fetched once and held client-side.
Netflix migrated from Oracle to Cassandra. Why? Oracle didn’t scale horizontally. Cassandra gave them write throughput and regional replication. But it wasn’t easy—they had to rewrite how they thought about data.
Netflix uses Flink + Kafka to power personalization, telemetry, chaos detection. It’s not just fancy data pipelines. It's user experience tuning, infra debugging, and alerting all rolled into one.
Netflix? They invented chaos engineering. Their infra isn’t just resilient, it’s antifragile. The more they test it, the stronger it gets. Moved to cloud-native, global deployments using Cassandra for multi-region replication.
Takeaway? Scale is less about the tech and more about owning the operating model.
Insights and Research
Most outages start at the integration layer—not the database.
Caching can reduce 60–90% of DB queries in well-architected systems.
Teams that invest in observability reduce mean time to resolution (MTTR) by 50%.
Event-driven architectures scale better and are easier to decouple.
Bottom Line: Scaling Is Culture, Not Code
Look, you can be a wizard with databases or know every AWS service under the sun, but if you’re only thinking in silos, your system’s gonna fall apart the moment things get real.
Truly scalable systems? They come from understanding all seven layers not just one or two you happen to like. The best architectures don’t just stack tools together. They’re built on a clear, connected vision where every piece data, infra, services, deployment, even the damn logging, plays nice with the others.
And here’s the thing: scalability isn’t just about “handling more users.” That’s baby’s first metric. It’s about keeping performance solid, systems reliable, and your dev team sane as everything grows. If your app melts every time traffic spikes, or if deploying a feature feels like defusing a bomb… guess what? You’re not scaling—you’re scrambling.
So whether you’re spinning up something new or untangling an ancient monolith, zoom out. Ask how each layer contributes to the big picture. Get good at all of it, not just your favorite parts. Because the systems that last the ones that actually scale—are the ones built by people who treat this stuff like a craft, not a checklist.
If you're serious about scale, ask the hard questions:
Is our client experience degrading under load?
Are we routing traffic smartly?
Is our app layer resilient or fragile?
Are we caching intelligently?
Can our DB survive a spike or region failure?
Are we learning from our data?
Can we deploy confidently, on a Friday, after lunch?
So what now?
Run a quick audit of your stack using the 7-layer model. Be honest—what’s brittle, what’s overworked, what’s missing?
Bring it up at your next architecture review. Share this doc. Ask the hard questions.
Don’t wait until you’re on fire to build for scale.
Oh, and if you’ve got scars, stories, or wins—hit reply. Would love to hear how you scale and don’t forget to subscribe.