
Can AI Catch Its Own Mistakes?
A tiny add-on reads internal signals to predict errors, no expensive fact-checkers needed

You’ve probably noticed: ChatGPT and other AI tools sometimes confidently give you wrong answers. They don’t know they’re wrong. They can’t feel confused. Research shows that modern language models fail to recognize around 40% to 60% percent of their own errors. So even if a model looks very accurate on benchmarks, it still misses many of its own mistakes.
AI systems generate fluent text but can't tell when they're hallucinating. To solve hallucination problem current solutions are -
Token probabilities → Simply checks the model’s own confidence score. But accuracy is only around 65%. That may sound okay, but in complex reasoning tasks it barely performs better than guessing. Models often say they are very confident even when the answer is completely wrong. It’s basically free.
Self-consistency → Here, we generate multiple answers and check if they correct. This improves accuracy to around 75%, but we are running the model many times for each query. For production systems, handling millions of requests, this becomes extremely expensive.
Reward models → In this approach, we train another very large model, sometimes with billions of parameters, just to judge outputs. Accuracy improves further, but infrastructure cost increases, response time slows down, and training requires expensive human-labeled data.
Proprietary judge systems → These often give strong performance, but every request must go to an external provider. That means added cost, extra latency, and dependence on another company’s system.
If you look at all of these together, you start seeing the pattern. Better accuracy usually means much higher cost or complexity.
How Researches Solves the Problem
In this paper researchers discussed on one novel idea to built Gnosis, a tiny lie detector system that watches what happens inside the AI while it thinks.
Think of it like this: Instead of waiting for a doctor to diagnose you, imagine a sensor that reads your pulse, breathing, and micro-expressions in real-time. It notices you’re stressed before you even realize it.
Gnosis does the same thing for AI. It reads:
Hidden states → The AI’s internal thoughts as they evolve
Attention patterns → Where the AI focuses while writing
These signals reveal when something’s off—even if the final text sounds confident.
Gnosis connects to a frozen text-generating system and captures two types of internal data:
Hidden states (the system's internal representations at each step) and
Attention maps (which tokens the system focuses on).
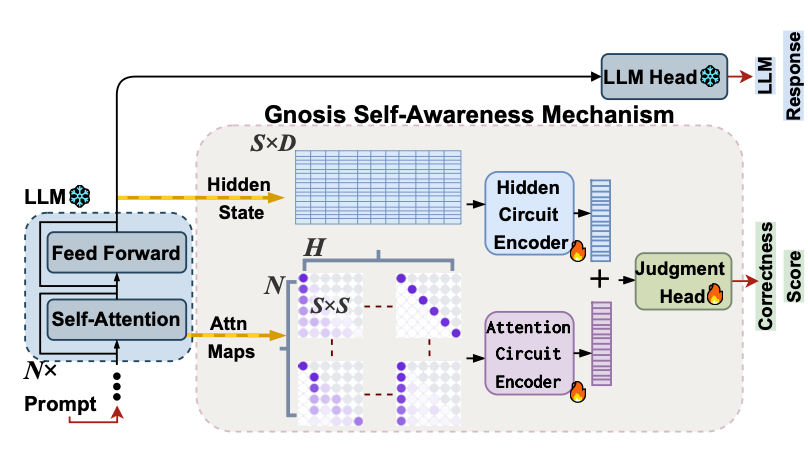
These variable-length traces are compressed into fixed-size summaries so processing cost stays constant regardless of answer length. Two small encoder networks extract patterns from each summary: one learns temporal changes in hidden states, and the other learns spatial patterns in attention. A tiny gated network combines both summaries and outputs a single correctness probability. The entire add-on uses only about 5 million parameters and runs in about 25 milliseconds.
The key insight: Gnosis is 1,000x smaller than typical AI checkers but performs better.
Thanks for reading The Neural Blueprint! If you found this useful, consider sharing it with someone who’s curious about AI reliability
What Researchers Found
The researchers tested Gnosis on math problems, trivia, and academic questions.
On math reasoning:
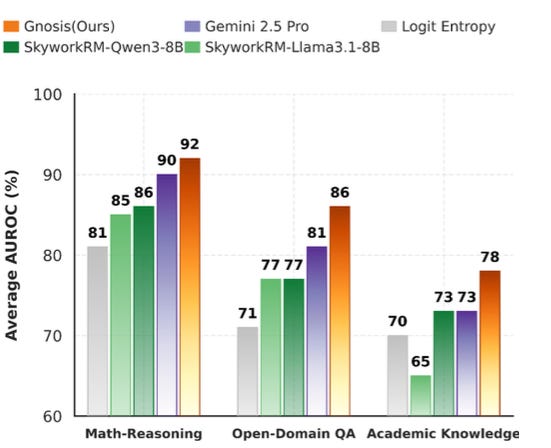
They evaluated Gnosis across three different domains: math reasoning, open-domain question answering, and academic knowledge.
And they compared it against four types of baselines: simple statistical indicators, large reward models, proprietary judge models, and learned probes.
First, math reasoning. These are competition-style problems from AMC12, AIME, and HMMT. They require multi-step reasoning, algebra, and careful logic. This is where models usually struggle the most.
Gnosis. 92% AUROC (Area Under the Receiver Operating Characteristic Curve).
In the context of Large Language Models (LLMs), it is a performance metric used to evaluate the ability of a model to distinguish between classes typically to differentiate between correct/incorrect, positive/negative, or safe/unsafe outputs
That matches the performance of Gemini 2.5 Pro, which is a proprietary model with billions of parameters accessed through an external API.
Skywork, an eight-billion-parameter reward model. It reaches about 85%. That is a seven-point gap.
To put that in perspective, Gnosis outperforms a model that is roughly sixteen hundred times larger.
And if we compare against simple baselines like logit entropy, which reaches around eighty-one percent, the improvement is even larger.
On the hardest reasoning tasks, internal signals give state-of-the-art performance.
Next, open-domain question answering using TriviaQA.
These are short factual questions. We might expect text-based judges to perform very well here.
But Gnosis still leads.
It reaches about 96% AUROC. Gemini comes in around 81%. Skywork around 77%. And a learned probe that only looks at the final token is much lower.
So Gnosis has a consistent lead across all baselines.
Even on short factual tasks, where the output text is simple, internal dynamics turn out to be more reliable.
Speed comparison:
External checker: 2,465 ms for long answers
Gnosis: 25 ms (99x faster)
Gnosis wasn’t trained on partial answers. But it works on them anyway.
After seeing just 40% of an answer, Gnosis already matches the full-answer accuracy of other methods.
Why this matters: AI could stop itself mid-generation when it senses trouble—saving time and preventing bad outputs.
Gnosis works best within AI families. It transfers well from a small model to its larger siblings. But it doesn’t work as a universal judge for completely different AI architectures.
It’s a self-awareness tool, not a one-size-fits-all solution.
📄 Paper: Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits
👥 Authors: Amirhosein Ghasemabadi & Di Niu, University of Alberta
Subscribe to The Neural Blueprint
By Vijendra
Deconstructing the architecture of modern AI systems