
Agent Lightning: Training Any AI Agent with Reinforcement Learning
How Microsoft's new framework lets you train any LangChain, AutoGen, or custom agent with reinforcement learning, no rewrites required

AI agents are everywhere now, handling customer queries, generating code, searching databases, orchestrating workflows. But here’s the problem: most agents still can’t learn from their mistakes. They’re stuck with whatever capabilities their underlying language model has, frozen in time from their last training run. When you deploy them on private data, unfamiliar tools, or complex multi-step tasks, they stumble. And unlike humans, they don’t get better through experience.
Researchers at Microsoft just released Agent Lightning, a framework that changes this equation entirely. It lets you apply reinforcement learning (RL) to train any AI agent, whether you built it with LangChain, OpenAI’s SDK, AutoGen, or raw code with essentially zero modifications to your existing agent logic.
The Core Problem Today
Training agents is hard for two reasons. First, agents are complex. Unlike a single LLM call that takes a prompt and returns an answer, agents make multiple LLM invocations with different prompts, call external tools, interact with APIs, and orchestrate dynamic workflows. A retrieval-augmented generation agent might generate a search query, retrieve documents, decide whether to refine the search, then finally answer.
Second, agents are diverse. Every application demands custom orchestration. A text-to-SQL agent needs database executors and error correction loops. A coding agent needs interpreters and test harnesses. A customer service bot needs CRM integrations and escalation logic. Existing RL frameworks assume static, single-turn tasks like math problems or preference alignment. They can’t handle this variability without forcing developers to rebuild their agents inside the training system.
The Key Ideas
Agent Lightning solves this through three conceptual moves.
First, it formulates agent execution as a Markov Decision Process (MDP). The state is the current snapshot of your agent all the variables that describe where it is in its workflow (user input, retrieved documents, generated queries, etc.). An action is the complete output from a single LLM call. When the LLM generates a response, that updates the state, triggering the next action. This formulation lets Agent Lightning treat any agent workflow as a sequence of state transitions, regardless of how complex or dynamic the orchestration is.
Second, it defines a unified data interface. During execution, Agent Lightning captures transitions; tuples of (input to the LLM, output from the LLM, reward). The input contains only what the LLM sees at that moment. The output is the text it generates. The reward measures quality either for that specific step (like “did the tool call succeed?”) or for the entire episode at the end. This interface is completely agnostic to how your agent works internally. It doesn’t care if you’re using templates, function calling, multi-agent orchestration, or raw Python loops. It just captures the data flowing through LLM invocations.
Third, it introduces LightningRL, a hierarchical RL algorithm. Traditional RL (Reinforcement Learning) for LLMs optimizes token-by-token generation in a single response. But agents need multi-turn optimization across many LLM calls. LightningRL first assigns credit from the episode-level return (final reward) down to each individual LLM call via a credit assignment module. Then it decomposes each call’s reward down to tokens using existing single-turn algorithms like GRPO, PPO, or REINFORCE++. This two-level design lets you plug in any standard LLM RL method without modification, while handling arbitrary multi-step agent logic.

The agent starts with
state₀ = {UserInput: “What caused the 2008 financial crisis?”}.
It calls the LLM, which generates a search query: “2008 financial crisis causes”.
That query becomes part of state₁.
The search tool retrieves documents, updating to
state₂ = {UserInput, Query, Passages}.
The LLM is called again to generate the final answer based on those passages, producing
state₃ = {UserInput, Query, Passages, Answer}.
A reward function scores the answer quality (say, 0.85 via F1 match).
Agent Lightning captured two transitions: (state₀, query, 0) and (state₂, answer, 0.85).
The credit assignment module distributes the final reward across both calls. Each transition is then optimized using standard token-level RL.Thanks for reading The Neural Blueprint! If you found this useful, consider sharing it with someone who’s curious about Agent Learning
What the Experiments Show
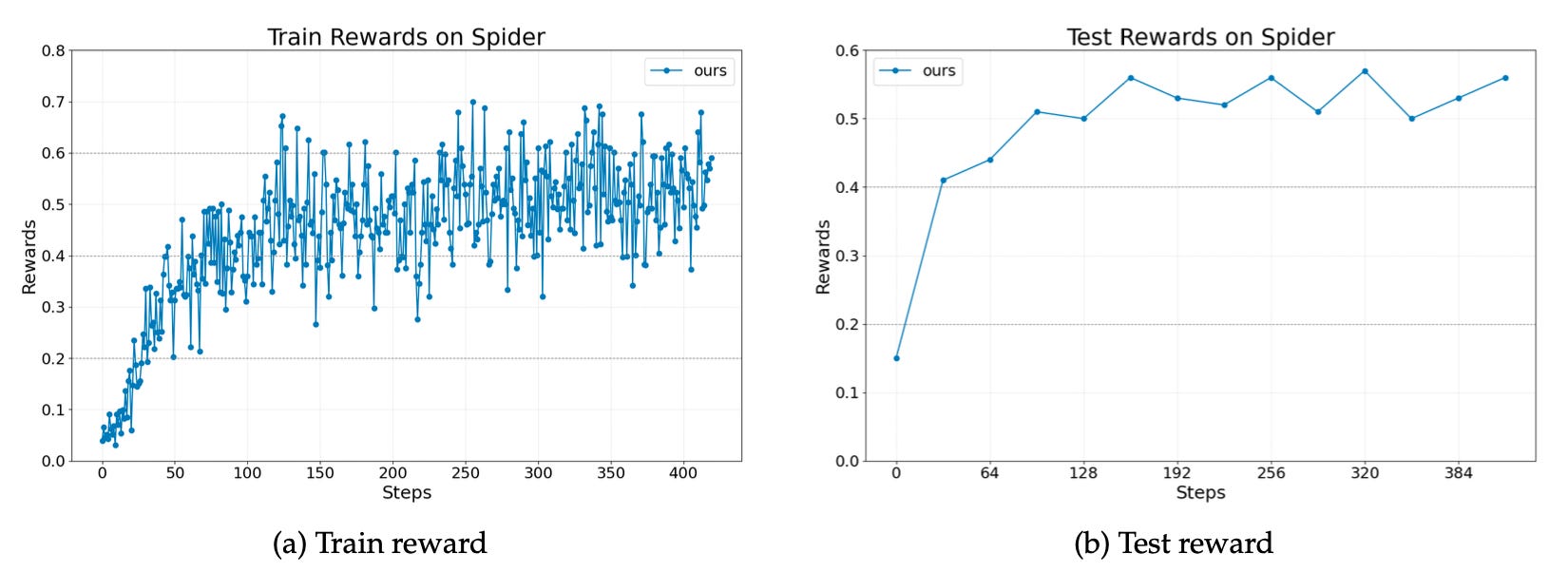
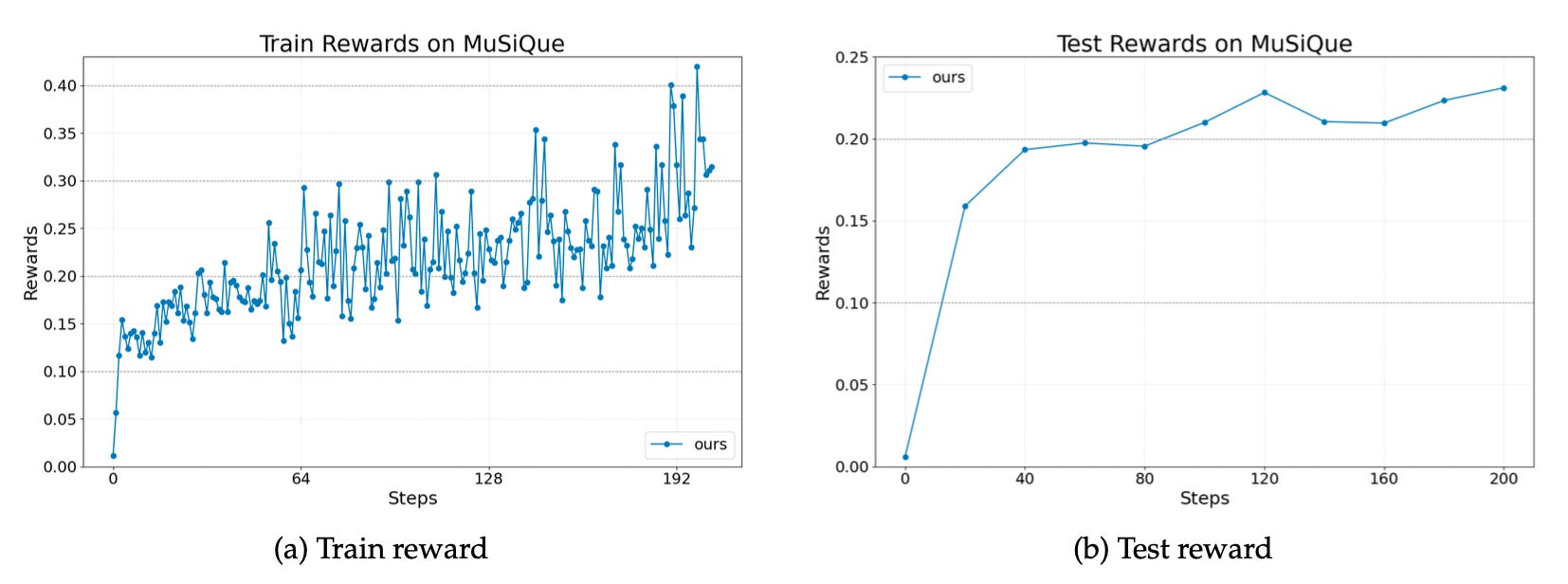
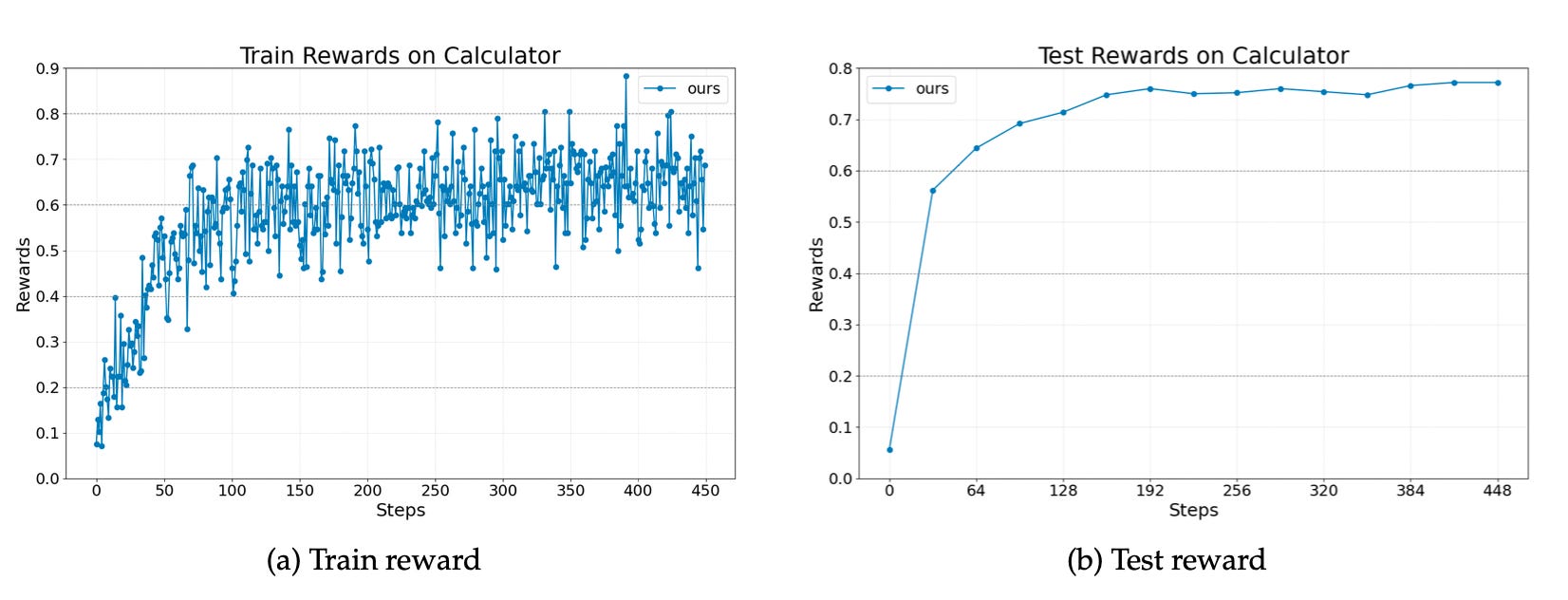
The researchers tested Agent Lightning on three tasks, each using a different framework. A text-to-SQL agent built with LangChain on the Spider dataset (complex queries across 200 databases). A retrieval-augmented generation agent using OpenAI Agents SDK on MuSiQue (multi-hop questions requiring compositional reasoning over all of Wikipedia). A math question-answering agent with calculator tool usage via AutoGen on Calc-X. All used Llama-3.2-3B-Instruct as the base model.
Across all three, training and test reward curves show stable, continuous improvement.
The text-to-SQL agent went from roughly 0.1 to 0.55 test reward over 384 steps.
The RAG agent improved from near-zero to 0.21 test reward over 200 steps on an extremely challenging benchmark.
The calculator agent climbed from 0.0 to 0.78 test reward over 448 steps.
These aren’t incremental tweaks they represent agents learning to handle complex reasoning, tool usage, and multi-step workflows that they initially failed at.
Why It Matters and to Whom
For practitioners, Agent Lightning means you can finally optimize agents on your private data and custom tools without rebuilding everything. Drop in your existing LangChain or AutoGen agent, add a reward function, run the training loop. Your agent learns which queries retrieve better documents, which SQL patterns avoid errors, which reasoning chains lead to correct answers.
For researchers, this framework opens up agent-generated data as a training resource. Agents interact with real environments at massive scale; far beyond what human annotation can provide. That data can now feed back into model improvement, potentially driving the next generation of foundation models.
For product teams, it bridges the gap between development and deployment. You can iterate on agent designs quickly, then use RL to continuously improve performance post-deployment as you collect real interaction data.
Strengths, Limitations, and Open Questions
Agent Lightning’s core strength is its complete decoupling of training from agent execution. The unified data interface and MDP formulation are genuinely framework-agnostic. The Training-Agent Disaggregation architecture with a Lightning Server handling GPU-intensive training and a Lightning Client managing agent execution is architecturally clean and scales well.
But there are limits. The current credit assignment simply gives each action equal share of the final return, which is naive. More sophisticated methods (learned value functions, heuristic-based assignment) could improve sample efficiency but aren’t implemented yet. The framework handles single-LLM multi-agent scenarios elegantly (one LLM playing different roles via prompts), but true multi-LLM coordination would require multi-agent RL techniques not yet integrated. The experiments use relatively small models (3B parameters) and moderate task complexity; scaling to frontier models and extremely long-horizon tasks remains unproven.
The paper also doesn’t deeply explore failure modes. What happens when reward functions are noisy or misspecified? How sensitive is training to hyper parameters across diverse agent types? What’s the sample efficiency compared to supervised fine-tuning when you do have step-by-step annotations?
Still, this represents a genuine step forward. Agent Lightning doesn’t just propose an algorithm; it delivers a usable system that works with real agent frameworks today. The examples in paper Appendix A show you can integrate it with ~20 lines of wrapper code. That’s the difference between a research idea and a tool people will actually use.
The future of AI agents isn’t just smarter base models. It’s agents that learn from deployment, that improve through interaction, that adapt to the specifics of your use case. Agent Lightning makes that future accessible to anyone building agents right now.
📄 Paper Link: https://arxiv.org/abs/2508.03680
👥 Authors: Xufang Luo, Yuge Zhang, Zhiyuan He et.
🔗 Code: Agent Lightning
PS: All images are taken from the paper.
Subscribe to The Neural Blueprint
By Vijendra
Deconstructing the architecture of modern AI systems